 [just appeared and accepted for publication, submitted papers]
[just appeared and accepted for publication, submitted papers]
[just appeared and accepted for publication, submitted papers]
Also available:
Most publications can be downloaded from this site. Otherwise, just ask me (nadal "at " lps.ens.fr).
Last modified on Aug. 25, 2018
Perceptual decision making is the subject of many experimental and theoretical studies. Whereas most modeling analysis are based on statistical processes of accumulation of evidence, less attention is being devoted to the modeling with attractor network dynamics, even though they describe well psychophysical and neurophysiological data. In particular, very few works confront attractor models predictions with data from continuous sequences of trials. Recently however, a biophysical competitive attractor network model has been used to describe such sequences of decision trials, and has been shown to reproduce repetition biases observed in perceptual decision experiments. Here we propose an extension of the reduced attractor network model of Wong and Wang (2006) to get more insights into such effects. We make explicit the conditions under which such network can perform a succession of decisions, and show that the model provides a mathematical framework for studying the effects of a trial on the decision made on the next one. We study in details the reaction times properties during a sequence of decision trials, and show that the model reproduces behavioral data, both qualitatively and quantitatively. In particular, we find that the decision made on the current trial is biased toward the one made on the previous trial. More remarkably, we show that, in the absence of any feedback about the correctness of the decision, the network exhibits post-error slowing, a subtle effect in agreement with empirical data.
back to the list without abstracts.
The cerebellum aids the learning and execution of fast coordinated movements, with acquired information being stored by plasticity of parallel fibre--Purkinje cell synapses. According to the current consensus, erroneously active parallel fibre synapses are depressed by complex spikes arising as climbing fibres signal movement errors. However, this theory cannot solve the credit assignment problem of using the limited information from a global movement evaluation to optimise behaviour by guiding the plasticity in numerous neurones. We identify the possible implementation of an algorithm solving this problem, whereby spontaneous complex spikes perturb ongoing movements, create an eligibility trace for plasticity and signal resulting error changes to guide plasticity. These error changes are extracted by adaptively cancelling the average error. This framework, stochastic gradient descent with estimated global errors, generates specific predictions for synaptic plasticity rules that contradict the current consensus. However, in vitro plasticity experiments under physiological conditions verified our predictions, highlighting the sensitivity of plasticity studies to unphysiological conditions. Using numerical and analytical approaches we demonstrate the convergence and estimate the capacity of learning in our implementation. Finally, a similar mechanism may operate during optimisation of action sequences by the basal ganglia, where dopamine could both initiate movements and signal rewards, analogously to the dual perturbation and correction role of the climbing fibre outlined here.
back to the list without abstracts.
We represent the functioning of the housing market and the processes that shape residential income segregation by introducing a spatial Agent-Based Model (ABM). Differently from traditional models in urban economics, we explicitly specify the behavior of buyers and sellers and the price formation mechanism. Buyers who differ by income select among heterogeneous neighborhoods using a probabilistic model of residential choice; sellers employ an aspiration level heuristic to set their reservation offer price; prices are determined through a continuous double auction. We first provide an approximate analytical solution of the ABM, shedding light on the structure of the model and on the effect of the parameters. We then simulate the ABM and find that: (i) a more unequal income distribution lowers the prices globally, but implies stronger segregation; (ii) a spike of the demand in one part of the city increases the prices all over the city; (iii) subsidies are more efficient than taxes in fostering social mixing.
back to the list without abstracts.
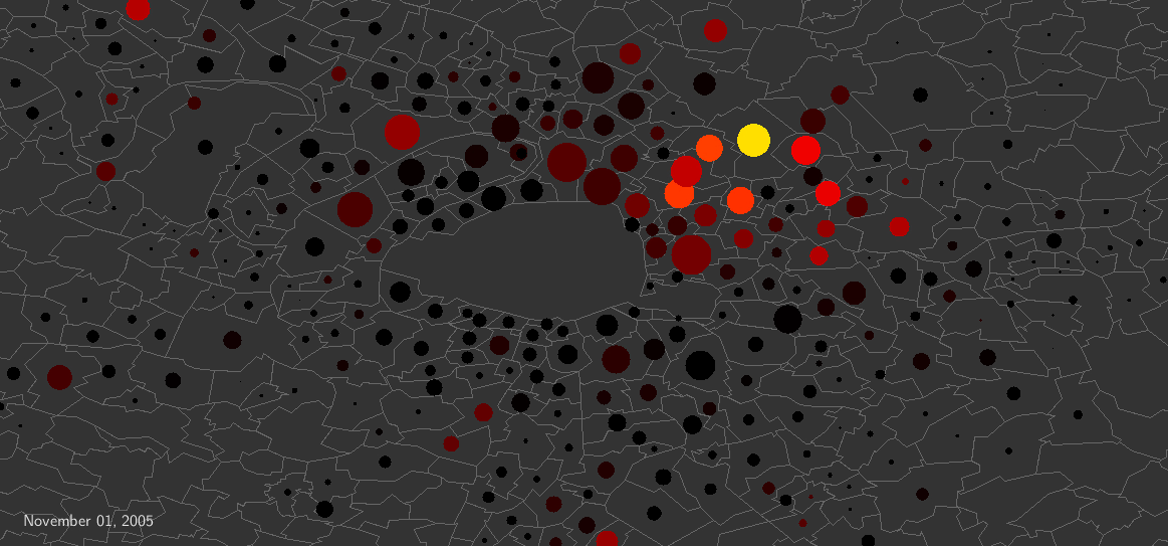
As a large-scale instance of dramatic collective behavior, the 2005 French riots started in a poor suburb of Paris, then spread in all of France, lasting about three weeks. Remarkably, although there were no displacements of rioters, the riot activity did traveled. Daily national police data to which we had access have allowed us to take advantage of this natural experiment to explore the dynamics of riot propagation. Here we show that an epidemic-like model, with less than 10 free parameters and a single sociological variable characterizing neighborhood deprivation, accounts quantitatively for the full spatio-temporal dynamics of the riots. This is the first time that such data-driven modeling involving contagion both within and between cities (through geographic proximity or media) at the scale of a country is performed. Moreover, we give a precise mathematical characterization to the expression ``wave of riots'', and provide a visualization of the propagation around Paris, exhibiting the wave in a way not described before. The remarkable agreement between model and data demonstrates that geographic proximity played a major role in the riot propagation, even though information was readily available everywhere through media. Finally, we argue that our approach gives a general framework for the modeling of spontaneous collective uprisings.
Videos: wave propagation in Paris area. Color: riot intensity. Size of the circles: for each municipality, in proportion of the size of the deprived population. Left: video based on the data after smoothing. Right: video based on the calibrated epidemiological model. See the paper for details.

Echos:
Altmetric, "Attention score": in the top 5% of all research outputs ever tracked by Altmetric (Aug. 7, 2018)
MIT Technology Review, Top Stories, Feb 3, 2017 - also in the Spanish edition
France Inter : « Les émeutes contagieuses », interview pour la séquence 'La Une de la science' de l’émission 'La tête au carré', 25 janvier 2018
Le Monde, « Les émeutes de 2005 vues comme une épidémie de grippe », Jan. 22, 2018
It is generally believed that when a linguistic item acquires a new meaning, its overall frequency of use rises with time with an S-shaped growth curve. Yet, this claim has only been supported by a limited number of case studies. In this paper, we provide the first corpus-based large-scale confirmation of the S-curve in language change. Moreover, we uncover another generic pattern, a latency phase preceding the S-growth, during which the frequency remains close to constant. We propose a usage-based model which predicts both phases, the latency and the S-growth. The driving mechanism is a random walk in the space of frequency of use. The underlying deterministic dynamics highlights the role of a control parameter which tunes the system at the vicinity of a saddle-node bifurcation. In the neighbourhood of the critical point, the latency phase corresponds to the diffusion time over the critical region, and the S-growth to the fast convergence that follows. The durations of the two phases are computed as specific first-passage times, leading to distributions that fit well the ones extracted from our dataset. We argue that our results are not specific to the studied corpus, but apply to semantic change in general.
See also:back to the list without abstracts.
Though numerous numerical studies have investigated language change,
grammaticalization and diachronic phenomena of language renewal have
been left aside, or so it seems. We argue that previous models,
dedicated to other purposes, make representational choices that cannot
easily account for this type of phenomenon. In this paper we propose a
new framework, aiming to depict linguistic renewal through numerical
simulations. We illustrate it with a specific implementation which
brings to light the phenomenon of semantic bleaching.
(article in French) (Copyright © ATALA 2016)
Related paper, in English, same authors: "Modeling Language Change: The Pitfall of Grammaticalization", Chapter in "Language in Complexity: The Emerging Meaning", Springer 2016, pp. 49-72. See also above.
back to the list without abstracts.
We introduce and analyze several variants of a system of differential
equations which model the dynamics of social outbursts, such as riots.
The systems involve the coupling of an explicit variable representing
the intensity of rioting activity and an underlying (implicit) field of
social tension. Our models include the effects of exogenous and
endogenous factors as well as various propagation mechanisms. From
numerical and mathematical analysis of these models we show that the
assumptions made on how different locations influence one another and
how the tension in the system disperses play a major role on the
qualitative behavior of bursts of social unrest. Furthermore, we analyze
here various properties of these systems, such as the existence of
traveling wave solutions, and formulate some new open mathematical
problems which arise from our work.
(Copyright © AIMS 2015)
back to the list without abstracts.
Addressing issues in social diversity, we introduce a model of housing
transactions
between agents heterogeneous in their willingness to pay. A key
assumption is that agents preferences for a place depend on both an
intrinsic attractiveness
and on the social characteristics of its neighborhood.
The stationary space distribution of income is analytically and
numerically characterized.
The main results are that socio-spatial segregation occurs whenever the
social influence is strong enough, but even so, some social
diversity is preserved at most locations. Comparing with the Parisian
housing
market, the results reproduce general trends concerning the
price distribution and the income spatial segregation.
© 2013 Elsevier B.V.
Related works:
L. Gauvin et al, , "Schelling segregation in an open city: a kinetically constrained Blume-Emery-Griffiths spin-1 system", 2010 - see below.
L. Gauvin et al, Phase diagram of a Schelling segregation model", 2009 - see below.
L. Gauvin, PhD Thesis, Modélisation de systèmes socio-économiques à l'aide des outils de physique statistique, UPMC, 2010.
back to the list without abstracts.
Entanglement between Demand and Supply in Markets with Bandwagon Goods
Journal of Statistical Physics: Volume 151, Issue 3 (2013), Page 494-522
(this article is part of the special issue Statistical Mechanics and Social Sciences, II)
preprint arXiv:1209.1321
Whenever customers'choices (e.g. to buy or not a given good) depend on others
choices (cases coined 'positive externalities' or 'bandwagon effect' in the
economic literature), the demand may be multiply valued: for a same posted
price, there is either a small number of buyers, or a large one -- in which
case one says that the customers coordinate. This leads to a dilemma for the seller:
should he sell at a high price, targeting a small number of buyers,
or at low price targeting a large number of buyers? In this paper we show that
the interaction between demand and supply is even more complex than expected,
leading to what we call the curse of coordination: the pricing strategy
for the seller which aimed at maximizing his profit corresponds to posting a
price which, not only assumes that the customers will coordinate, but also lies
very near the critical price value at which such high demand no more exists.
This is obtained by the detailed mathematical analysis of a particular model
formally related to the Random Field Ising Model and to a model introduced in social sciences by T. C. Schelling in the 70's.
(Copyright © Springer 2012)
back to the list without abstracts.
Between order and disorder: a 'weak law' on recent electoral behavior among urban voters?
PLoS ONE 7(7): e39916 (published: July 25, 2012).
preprint arXiv:1202.6307
A new viewpoint on electoral involvement is proposed from the study of the statistics of the proportions of abstentionists, blank and null, and votes according to list of choices, in a large number of national elections in different countries. Considering 11 countries without compulsory voting (Austria, Canada, Czech Republic, France, Germany, Italy, Mexico, Poland, Romania, Spain and Switzerland), a stylized fact emerges for the most populated cities when one computes the entropy associated to the three ratios, which we call the entropy of civic involvement of the electorate. The distribution of this entropy (over all elections and countries) appears to be sharply peaked near a common value. This almost common value is typically shared since the 1970's by electorates of the most populated municipalities, and this despite the wide disparities between voting systems and types of elections. Performing different statistical analyses, we notably show that this stylized fact reveals particular correlations between the blank/null votes and abstentionists ratios. We suggest that the existence of this hidden regularity, which we propose to coin as a `weak law on recent electoral behavior among urban voters', reveals an emerging collective behavioral norm characteristic of urban citizen voting behavior in modern democracies. Analyzing exceptions to the rule provide insights into the conditions under which this normative behavior can be expected to occur.
back to the list without abstracts.
Storage of correlated patterns in standard and bistable Purkinje cell models
PLoS Computational Biology, 8(4): e1002448 (2012)
open access -
The cerebellum has long been considered to undergo supervised learning, with climbing fibers acting as a 'teaching' or 'error' signal. Purkinje cells (PCs), the sole output of the cerebellar cortex, have been considered as analogs of perceptrons storing input/output associations. In support of this hypothesis, a recent study found that the distribution of synaptic weights of a perceptron at maximal capacity is in striking agreement with experimental data in adult rats. However, the calculation was performed using random uncorrelated inputs and outputs. This is a clearly unrealistic assumption since sensory in- puts and motor outputs carry a substantial degree of temporal correlations. In this paper, we consider a binary output neuron with a large number of inputs, which is required to store associations between temporally correlated sequences of binary inputs and outputs, modelled as Markov chains. Storage capacity is found to increase with both input and output correlations, and diverges in the limit where both go to unity. We also investigate the capacity of a bistable output unit, since PCs have been shown to be bistable in some experimental conditions. Bistability is shown to enhance storage capacity whenever the output correlation is stronger than the input correlation. Distribution of synaptic weights at maximal capacity is shown to be independent on correlations, and is also unaffected by the presence of bistability.
back to the list without abstracts.
Reaction-times in perceptual tasks are the subject of many experimental
and theoretical studies. With the neural decision making process as main
focus, most of these works concern discrete (typically binary) choice
tasks, implying the identification of the stimulus as an exemplar of a
category. Here we address issues specific to the perception of
categories (e.g. vowels, familiar faces, ...), making a clear
distinction between identifying a category (an element of a discrete
set) and estimating a continuous parameter (such as a direction). We
exhibit a link between optimal Bayesian decoding and coding efficiency,
the latter being measured by the mutual information between the discrete
category set and the neural activity. We characterize the properties of
the best estimator of the likelihood of the category, when this
estimator takes its inputs from a large population of stimulus-specific
coding cells. Adopting the diffusion-to-bound approach to model the
decisional process, this allows to relate analytically the bias and
variance of the diffusion process underlying decision making to
macroscopic quantities that are behaviorally measurable. A major
consequence is the existence of a quantitative link between reaction
times and discrimination accuracy. The resulting analytical expression
of mean reaction times during an identification task accounts for
empirical facts, both qualitatively (e.g. more time is needed to
identify a category from a stimulus at the boundary compared to a
stimulus lying within a category), and quantitatively (working on
published experimental data on phoneme identification tasks).
Copyright © 2012, Elsevier.
Related works:
Same authors, "Neural Coding of Categories: Information Efficiency and Optimal Population Codes", J. of Comput. Neuroscience 2008, here.
Same authors, "From Exemplar Theory to Population Coding and Back - An Ideal Observer Approach" (preprint.pdf), proceedings of the workshop "Exemplar-Based Models of Language Acquisition and Use", Dublin, 2007.
Laurent Bonnasse-Gahot, PhD Thesis, Modélisation du codage neuronal de catégories et étude des conséquences perceptives, EHESS, 2009.
back to the list without abstracts.
In the 70s Schelling introduced a multiagent model to describe the
segregation dynamics that may occur with individuals having only weak
preferences for "similar" neighbors. Recently variants of this model
have been discussed, in particular, with emphasis on the links with
statistical physics models. Whereas these models consider a fixed number
of agents moving on a lattice, here, we present a version allowing for
exchanges with an external reservoir of agents. The density of agents is
controlled by a parameter which can be viewed as measuring the
attractiveness of the city lattice. This model is directly related to
the zero-temperature dynamics of the Blume-Emery-Griffiths spin-1 model,
with kinetic constraints. With a varying vacancy density, the dynamics
with agents making deterministic decisions leads to a variety of
"phases" whose main features are the characteristics of the interfaces
between clusters of agents of different types. The domains of existence
of each type of interface are obtained analytically as well as
numerically. These interfaces may completely isolate the agents leading
to another type of segregation as compared to what is observed in the
original Schelling model, and we discuss its possible socioeconomic
correlates.
Copyright © 2010 The American Physical Society
Related works:
Same authors, "Phase diagram of a Schelling segregation model", 2009 - see below.
L. Gauvin, A. Vignes and J.-P. Nadal, "Modeling urban housing market dynamics: can the socio-spatial segregation preserve some social diversity?", JEDC 2013 - see above.
L. Gauvin, PhD Thesis, Modélisation de systèmes socio-économiques à l'aide des outils de physique statistique, UPMC, 2010.
back to the list without abstracts.
A single social phenomenon (such as crime, unemployment or birth rate) can be observed through temporal series corresponding to units at different levels (cities, regions, countries...). Units at a given local level may follow a collective trend imposed by external conditions, but also may display fluctuations of purely local origin. The local behavior is usually computed as the difference between the local data and a global average (e.g. a national average), a view point which can be very misleading. In this article, we propose a method for separating the local dynamics from the global trend in a collection of correlated time series. We take an independent component analysis approach in which we do not assume a small average local contribution in contrast with previously proposed methods. We first test our method on financial time series for which various data analysis tools have already been used. For the S&P500 stocks, our method is able to identify two classes of stocks with marked different behaviors: the `followers' (stocks driven by the collective trend), and the `leaders' (stocks for which local fluctuations dominate). Furthermore, as a byproduct contributing to its validation, the method also allows to classify stocks in several groups consistent with industrials sectors. We then consider crime rate series, a domain where the separation between global and local policies is still a major subject of debate. We apply our method to the states in the US and the regions in France. In the case of the US data, we observe large fluctuations in the transition period of mid-70's during which crime rates increased significantly, whereas since the 80's, the state crime rates are governed by external factors, and the importance of local specificities being decreasing.
Echo in the nonacademic press: Where local policy matters, 16 April 2010, in Emerging Health Threats Forum (a not-for-profit Community Interest Company, established with support from the UK's Health Protection Agency).
back to the list without abstracts.
This paper summarizes the effects of social influences in a monopoly market with heterogeneous agents. The market equilibria are presented in the limiting case of global influence. Considering static profit maximization there may exist two different regimes: to sell either to a large fraction of customers at a low price, or to a small fraction of them at a higher price. This arises for numerous mono-modal distributions of idiosyncratic willingness to pay if the social influence is strong enough. The seller's optimal strategy switches from one regime to the other at parameter values where the demand has two different Nash equilibria; but the strategy of posting low prices to attract large fractions of buyers may fail due to a lack of coordination.
back to the list without abstracts.
Basic evidences on non-profit making and other forms of benevolent-based organizations reveal a rough partition of members between some {\em pure consumers} of the public good (free-riders) and {\em benevolent} individuals (cooperators). We study the relationship between the community size and the level of cooperation in a simple model where the utility of joining the community is proportional to its size. We assume an idiosyncratic willingness to join the community ; cooperation bears a fixed cost while free-riding bears a (moral) idiosyncratic cost proportional to the fraction of cooperators. We show that the system presents two types of equilibria: fixed points (Nash equilibria) with a mixture of cooperators and free-riders and cycles where the size of the community, as well as the proportion of cooperators and free-riders, vary periodically.
back to the list without abstracts.
The collective behavior in a variant of Schelling's segregation model is characterized with methods borrowed from statistical physics, in a context where their relevance was not conspicuous. A measure of segregation based on cluster geometry is defined and several quantities analogous to those used to describe physical lattice models at equilibrium are introduced. This physical approach allows to distinguish quantitatively several regimes and to characterize the transitions between them, leading to the building of a phase diagram. Some of the transitions evoke empirical sudden ethnic turnovers. We also establish links with 'spin-1' models in physics. Our approach provides generic tools to analyze the dynamics of other socio-economic systems.
Related works:
Same authors, "Schelling segregation in an open city: a kinetically constrained Blume-Emery-Griffiths spin-1 system", 2010 - see above.
L. Gauvin, A. Vignes and J.-P. Nadal, "Modeling urban housing market dynamics: can the socio-spatial segregation preserve some social diversity?", JEDC 2013 - see above.
L. Gauvin, PhD Thesis, Modélisation de systèmes socio-économiques à l'aide des outils de physique statistique, UPMC, 2010.
back to the list without abstracts.
back to the list without abstracts.
We consider a model of socially interacting individuals that make a
binary choice in a context of positive additive endogenous
externalities. It encompasses as particular cases several models from
the sociology and economics literature. We extend previous results to
the case of a general distribution of idiosyncratic preferences, called
here Idiosyncratic Willingnesses to Pay (IWP).
Positive additive externalities yield a family of inverse demand
curves that include the classical downward sloping ones but also new
ones with non constant convexity. When $j$, the ratio of the social
influene strength to the standard deviation of the IWP distribution, is
small enough, the inverse demand is a classical monotonic (decreasing)
function of the adoption rate. Even if the IWP distribution is
mono-modal, there is a critical value of $j$ above which the inverse
demand is non monotonic, decreasing for small and high adoption rates,
but increasing within some intermediate range. Depending on the price
there are thus either one or two equilibria.
Beyond this first result, we exhibit the {\em generic} properties of
the boundaries limiting the regions where the system presents different
types of equilibria (unique or multiple). These properties are shown to
depend {\em only} on qualitative features of the IWP distribution:
modality (number of maxima), smoothness and type of support (compact or
infinite).
The main results are summarized as {\em phase diagrams} in the space of
the model parameters, on which the regions of multiple equilibria are
precisely delimited.
back to the list without abstracts.
This paper deals with the analytical study of coding a discrete set of categories
by a large assembly of neurons. We consider population coding schemes, which can
also be seen as instances of exemplar models proposed in the literature to account for
phenomena in the psychophysics of categorization. We quantify the coding efficiency
by the mutual information between the set of categories and the neural code, and we
characterize the properties of the most efficient codes, considering different regimes
corresponding essentially to different signal-to-noise ratio. One main outcome is
to find that, in a high signal-to-noise ratio limit, the Fisher information at the
population level should be the greatest between categories, which is achieved by
having many cells with the stimulus-discriminating parts (steepest slope) of their
tuning curves placed in the transition regions between categories in stimulus space.
We show that these properties are in good agreement with both psychophysical data
-- from different domains such as object recognition and speech perception --,
and with the neurophysiology of the inferotemporal cortex in the monkey, a cortex
area known to be specifically involved in classification tasks.
(Copyright © Springer)
Related works:
Same authors, "Perception of categories: from coding efficiency to reaction times", Brain Research, 2012, here.
Same authors, "From Exemplar Theory to Population Coding and Back - An Ideal Observer Approach" (preprint.pdf), proceedings of the workshop "Exemplar-Based Models of Language Acquisition and Use", Dublin, 2007.
Laurent Bonnasse-Gahot, PhD Thesis, Modélisation du codage neuronal de catégories et étude des conséquences perceptives, EHESS, 2009.
back to the list without abstracts.
Crime is an economically relevant activity. It may represent a mechanism
of wealth distribution but also a social and economic burden because of
the interference with regular legal activities and the cost of the law
enforcement system. Sometimes it may be less costly for the society to
allow for some level of criminality. However, a drawback of such a
policy is that it may lead to a high increase of criminal activity, that
may become hard to reduce later on. Here we investigate the level of
law enforcement required to keep crime within acceptable limits. A sharp
phase transition is observed as a function of the probability of
punishment. We also analyze other consequences of criminality as the
growth of the economy, the inequality in the wealth distribution (the
Gini coefficient) and other relevant quantities under different
scenarios of criminal activity and probabilities of apprehension.
(Copyright © EDP Sciences, Società italiana di Fisica, Springer-Verlag 2009)
back to the list without abstracts.
We consider a social system of interacting heterogeneous agents with
learning abilities, a model close to Random Field Ising Models, where
the random field corresponds to the idiosyncratic willingness to pay.
Given a fixed price, agents decide repeatedly whether to buy or not a
unit of a good, so as to maximize their expected utilities. We show that
the equilibrium reached by the system depends on the nature of the
information agents use to estimate their expected utilities.
(Copyright © 2008 Elsevier B.V. )
back to the list without abstracts.
Much research effort into synaptic plasticity has
been motivated by the idea that modifications of synaptic weights (or
strengths or efficacies) underlie learning and memory. Here, we examine
the possibility of exploiting the statistics of experimentally measured
synaptic weights to deduce information about the learning process.
Analysing distributions of synaptic weights requires a theoretical
framework to interpret the experimental measurements, but the results
can be unexpectedly powerful, yielding strong constraints on possible
learning theories as well as information that is difficult to obtain by
other means, such as the information storage capacity of a cell. We
review the available experimental and theoretical techniques as well as
important open issues.
(Copyright © 2007 Elsevier B.V)
back to the list without abstracts.
Phonological rules relate surface phonetic word forms to abstract
underlying forms that are stored in the lexicon. Infants must thus
acquire these rules in order to infer the abstract representation of
words. We implement a statistical learning algorithm for the acquisition
of one type of rule, namely allophony, which introduces
context-sensitive phonetic variants of phonemes. This algorithm is based
on the observation that different realizations of a single phoneme
typically do not appear in the same contexts (ideally, they have
complementary distributions). In particular, it measures the
discrepancies in context probabilities for each pair of phonetic
segments. In Experiment 1, we test the algorithm.s performances on a
pseudo-language and show that it is robust to statistical noise due to
sampling and coding errors, and to non-systematic rule application. In
Experiment 2, we show that a natural corpus of semiphonetically
transcribed child-directed speech in French presents a very large number
of near-complementary distributions that do not correspond to existing
allophonic rules. These spurious allophonic rules can be eliminated by a
linguistically motivated filtering mechanism based on a phonetic
representation of segments. We discuss the role of a priori linguistic
knowledge in the statistical learning of phonology.
(Copyright © 2005 Elsevier B.V)
back to the list without abstracts.
We explore the effects of social influence in a simple market model in
which a large number of agents face a binary choice: to buy/not to buy a
single unit of a product at a price posted by a single seller (monopoly
market). We consider the case of positive externalities: an
agent is more willing to buy if other agents make the same decision. We
consider two special cases of heterogeneity in the individuals' decision
rules, corresponding in the literature to the Random Utility Models of
Thurstone, and of McFadden and Manski. In the first one the
heterogeneity fluctuates with time, leading to a standard model in
Physics: the Ising model at finite temperature (known as annealed
disorder) in a uniform external field. In the second approach the
heterogeneity among agents is fixed; in Physics this is a particular
case of quenched disorder models known as random field Ising model, at
zero temperature. We study analytically the equilibrium properties of
the market in the limiting case where each agent is influenced by all
the others (the mean field limit), and we illustrate some dynamic
properties of these models making use of numerical simulations in an
Agent based Computational Economics approach.
(Copyright © 2005 Taylor & Francis)
back to the list without abstracts.
Motivation: We consider any collection of microarrays that can be ordered to form a progression,
as a function of time, or severity of disease, or dose of a stimulant, for example. By plotting the
expression level of each gene as a function of time, or severity, or dose, we form an expression
series, or curve, for each gene. While most of these curves will exhibit random fluctuations, some
will contain pattern, and it is these genes which are most likely associated with the independent
variable.
Results: We introduce a method of identifying pattern and hence genes in microarray expression
curves without knowing what kind of pattern to look for. Key to our approach is the sequence
of ups and downs formed by pairs of consecutive data points in each curve. As a benchmark, we
blindly identified yeast cell cycles genes without selecting for periodic or any other anticipated
behaviour.
(Copyright © 2005 Oxford Journals)
Related publications by K. Willbrand (LPS ENS) and Th. Fink (Inst. Curie): see here.
back to the list without abstracts.
In this paper, we consider a discrete choice model where heterogeneous
agents are subject to mutual influences. We explore some consequences on
the market's behaviour, in the simplest case of a uniform willingness
to pay distribution. We exhibit a first-order phase transition in the
profit optimization by the monopolist: if the social influence is strong
enough, there is a regime where, if the mean willingness to pay
increases, or if the production costs decrease, the optimal solution for
the monopolist jumps from a solution with a high price and a small
number of buyers, to a solution with a low price and a large number of
buyers. Depending on the path of prices adjustments by the monopolist,
simulations show hysteretic effects on the fraction of buyers.
(Copyright © 2005 Elsevier B.V.)
back to the list without abstracts.
We propose an agent-based model of a single-asset financial market,
described in terms of a small number of parameters, which generates
price returns with statistical properties similar to the stylized facts
observed in financial time series. Our agent-based model generically
leads to the absence of autocorrelation in returns, self-sustaining
excess volatility, mean-reverting volatility, volatility clustering and
endogenous bursts of market activity non-attributable to external noise.
The parsimonious structure of the model allows the identification of
feedback and heterogeneity as the key mechanisms leading to these
effects.
(Copyright © Institute of Physics and IOP Publishing Limited 2005)
back to the list without abstracts.
The interpretation of geophysical data, such as images of subsurface
rocks (seismic data, borehole scans), requires one in particular to
perform an elaborate segmentation analysis on strongly textured,
anisotropic, and not necessarily brightness-contrasted images. In this
paper we explore the possibility of deriving new segmentation algorithms
from recent advances in the neural modelling of pre-attentive
segmentation in human vision. More specifically we consider a neural
model proposed by Zhaoping Li. First, we reproduce some specific results
obtained by Zhaoping Li on simple artificial and real images sharing
some textural characteristics with geophysical data. Next, from the
analysis of the model behaviour, we propose an image processing workflow
depending on the textural characteristics and on the type of
segmentation (contour enhancement or texture edge detection) one is
interested in. With this algorithm one gets promising results: from the
computation of a single attribute one extracts the oriented textured
feature boundaries without prior classification.
(Copyright © Institute of Physics and IOP Publishing Limited 2004)
back to the list without abstracts.
It is widely believed that synaptic modifications under lie learning and
memory. However, few studies have examined what can be deduced about
the learning process from the distribution of synaptic weights. We
analyze the perceptron, a prototypical feedforward neural network, and
obtain the optimal synaptic weight distribution for a perceptron with
excitatory synapses. It contains more than 50% silent synapses, and
this fraction increases with storage reliability: silent synapses are
therefore a necessary byproduct of optimizing learning and reliability.
Exploiting the classical analogy between the perceptron and the
cerebellar Purkinje cell, we fitted the optimal weight distribution to
that measured for granule cell-Purkinje cell synapses. The two
distributions agreed well, suggesting that the Purkinje cell can learn
up to 5 kilobytes of information in the form of 40,000 input-output
associations.
(Copyright © 2004 by Cell Press)
back to the list without abstracts.
This letter suggests that in biological organisms, the perceived structure
of reality, in particular the notions of body, environment, space, object,
and attribute, could be a consequence of an effort on the part of brains to
account for the dependency between their inputs and their outputs in terms
of a small number of parameters. To validate this idea, a
procedure is demonstrated whereby the brain of an organism with
arbitrary input and output connectivity can deduce the dimensionality
of the rigid group of the space underlying its input-output relationship, that is
the dimension of what the organism will call physical space.
(© 2003 The MIT Press)
back to the list without abstracts.
Natural images are complex but very structured objects and, in spite of its com-
plexity, the sensory areas in the neocortex in mammals are able to devise learned
strategies to encode them endciently. How is this goal achieved? In this paper, we
will discuss the multiscaling approach, which has been recently used to derive a
redundancy reducing wavelet basis. This kind of representation can be statistically
learned from the data and is optimally adapted for image coding; besides, it presents
some remarkable features found in the visual pathway. We will show that the
introduction of oriented wavelets is necessary to provide a complete description, which
stresses the role of the wavelets as edge detectors.
(Copyright © 2003 Elsevier Science Ltd.)
back to the list without abstracts.
We present a model of opinion dynamics in which agents adjust continuous
opinions as a result of random binary encounters whenever their
difference in opinion is below a given threshold. High thresholds yield
convergence of opinions toward an average opinion, whereas low
thresholds result in several opinion clusters. The model is further
generalized to network interactions, threshold heterogeneity, adaptive
thresholds, and binary strings of opinions.
(Copyright © 2002 Wiley Periodicals, Inc., A Wiley Company)
back to the list without abstracts.
We show that the lower bound to the critical fraction of data needed to infer (learn) the
orientation of the anisotropy axis of a probability distribution, determined by Herschkowitz
and Opper [Phys.Rev.Lett. 86, 2174 (2001)], is not always valid. If there is some
structure in the data along the anisotropy axis, their analysis is incorrect, and learning is
possible with much less data points.
[© 2002 by The American Physical Society]
This article has been selected for the February 15, 2002 issue of the Virtual Journal of Biological Physics Research published by the American Institute of Physics and the American Physical Society.
back to the list without abstracts.
We address the problem of blind source separation in the case of a
time dependent mixture matrix.
For a slowly and smoothly varying mixture matrix, we propose a systematic expansion
which leads to a practical algebraic solution when
stationary and ergodic properties hold for the sources.
[© 2000 Elsevier Science B. V.]
back to the list without abstracts.
We investigate the information processing of a linear mixture of independent sources of different magnitudes. In particular we consider the case where a number m of the sources can be considered as “strong” as compared to the other ones, the “weak” sources. We find that it is preferable to perform blind source separation in the space spanned by the strong sources, and that this can be easily done by first projecting the signal onto the m largest principal components. We illustrate the analytical results with numerical simulations.
back to the list without abstracts.
With the aim of identifying the physical causes of variability of a
given dynamical system, the geophysical community has made an extensive
use of classical component extraction techniques such as principal
component analysis (PCA) or rotational techniques (RT). We introduce a
recently developed algorithm based on information theory: independent
component analysis (ICA). This new technique presents two major
advantages over classical methods. First, it aims at extracting
statistically independent components where classical techniques search
for decorrelated components (i.e., a weaker constraint). Second, the
linear hypothesis for the mixture of components is not required. In this
paper, after having briefly summarized the essentials of classical
techniques, we present the new method in the context of geophysical time
series analysis. We then illustrate the ICA algorithm by applying it to
the study of the variability of the tropical sea surface temperature
(SST), with a particular emphasis on the analysis of the links between
El Niño Southern Oscillation (ENSO) and Atlantic SST variability. The
new algorithm appears to be particularly efficient in describing the
complexity of the phenomena and their various sources of variability in
space and time.
(© 2000 by the American Geophysical Union)
back to the list without abstracts.
Dans le but d'identifier les causes physiques de la variabilité d'un
système dynamique, la communauté géophysique utilise de façon intensive
les techniques statistiques d'extraction de composantes. Un algorithme
récemment développé, fondé sur la théorie de l'information, est
introduit dans ce travail : l'analyse en composantes indépendantes
(ACI). Cette technique présente deux avantages majeurs sur les
techniques classiques. Premièrement, elle a pour but d'extraire des
composantes statistiquement indépendantes, là où les techniques
classiques cherchent uniquement la décorrélation. Deuxièmement,
l'hypothèse linéaire pour le mélange des composantes n'est pas requise.
Cette nouvelle technique est présenté dans le contexte de l'analyse de
séries temporelles géophysiques. L'algorithme ACI est appliqué à l'étude
de la variabilité de la température de surface de l'océan (TSO)
tropical, avec une attention particulière pour l'analyse des liens entre
le phénomène El Niño/Southern Oscillation (Enso) et la variabilité de
la TSO Atlantique.
(© 1999 - Académie des Sciences/ Éditions Scientifiques et Médicales Elsevier SAS)
back to the list without abstracts.
Recent works in parameter estimation and neural coding have demonstrated
that optimal performance are related to
the mutual information between parameters and data. In this paper, we study the mutual information between parameter and data for a family of supervised and unsupervised
learning tasks. The parameter is a possibly, but not necessarily, high-dimensional vector. We derive exact
bounds and asymptotic behaviors for the mutual information as a function of the data size and of some
properties of the probability of the data given the parameter. We compare these exact results with the
predictions of replica calculations. We briefly discuss the universal properties of the mutual information
as a function of data size.
[© 1999 The American Physical Society]
Short version presented at NIPS*98:
Didier Herschkowitz and Jean-Pierre Nadal, "Unsupervised clustering:
the mutual information between parameters and observations", in Advances in Neural Information
Processing Systems 11, M. S. Kearns, S. A. Solla, D. A. Cohn, eds., MIT Press 1999, pp. 232-238.
Related works:
D. Herschkowitz and M. Opper, "Retarded Learning: Rigorous Results from Statistical Mechanics",
Phys.Rev.Lett. 86, 2174 (2001).
and above.
back to the list without abstracts.
We present a formal, although simple, approach to the modeling of a buyer behavior in the type of markets studied in Weisbuch, Kirman and Herreiner, 1995. We compare possible buyer's choice functions, such as linear or logit function. We study the resulting behaviour, showing that they depend on some convexity properties of the choice function. Our results make use of standard Statistical Physics concepts and techniques. In particular we use the "mean field approximation" to derive the long term behaviour of buyers, and we show that the standard "logit" choice function can be justified from a general optimization principle, leading to an exploration-exploitation compromise.
back to the list without abstracts.
In the context of parameter estimation and model
selection, it is only quite recently that
a direct link between the Fisher information
and information theoretic quantities has been exhibited. We
give an interpretation of this link within the standard
framework of information theory.
We show that in the context of
population coding,
the mutual information between the activity of a large array of neurons and
a stimulus to which the neurons are tuned is naturally related
to the Fisher information.
In the light of this result we consider the optimization
of the tuning curves parameters
in the case of neurons responding to a stimulus
represented by an angular variable.
(Copyright © The MIT Press)
back to the list without abstracts.
Independent Component Analysis (ICA), and in particular
Blind Source Separation (BSS),
can be obtained from the maximization of mutual information,
as first shown in Nadal and Parga 1994.
The practical interest of this information theoretic
based cost function was then demonstrated in several BSS applications
(see e.g. Bell and Sejnowski 1995, ICA at CNL).
In the present paper the main
result of Nadal and Parga 1994 is extended to the case
of stochastic outputs. More precisely,
we prove that maximization of mutual information between the output
and the input of a feedforward neural network leads to
full redundancy reduction
under the following sufficient
conditions:
(1) the input signal is a (possibly nonlinear) invertible mixture
of independent components; (2) there is no input noise;
(3) the activity of each output neuron is a (possibly) stochastic variable
with a probability distribution depending on the stimulus through
a deterministic function of the inputs; both the probability
distributions and the functions can be different
from neuron to neuron; (4) optimization of the mutual information
is performed over all these deterministic functions.
back to the list without abstracts.
We show that the statistics of an edge type variable in natural
images exhibits self-similarity properties which resemble those of
local energy dissipation in turbulent flows. Our results show that self-similarity
and extended self-similarity hold remarkably for the statistics of the
local edge variance, and that the very same models can be used to predict
all of the associated exponents. These results suggest using natural
images as a laboratory for testing more elaborate scaling models of
interest for the statistical description of turbulent flows. The properties we
have exhibited are relevant for the modeling of the early visual
system: They should be included in models designed for the prediction of receptive fields.
[© 1998 by The American Physical Society]
back to the list without abstracts.
We study the information processing properties of a binary channel receiving data from a gaussian source. A systematic comparison with linear processing is done. A remarkable property of the binary sytem is that, as the ratio $\alpha$ between the number of output and input units increases, binary processing becomes equivalent to linear processing with a quantization output noise that depends on $\alpha$. In this regime , that holds up to $O( \alpha^{-4})$ , information processing occurs as if populations of $\alpha$ binary units cooperate to represent one $\alpha$-bit output unit. Unsupervised learning of a noisy environment by optimization of the parameters of the binary channel is also considered.
back to the list without abstracts.
In the context of both sensory coding and signal processing,
building factorized codes has been shown to be an efficient
strategy. In a wide variety of situations, the signal to be
processed is a linear mixture of statistically independent sources.
Building a factorized code is then equivalent to performing blind
source separation. Thanks to the linear structure of the data, this
can be done, in the language of signal processing, by finding an
appropriate linear filter, or equivalently, in the language of
neural modeling, by using a simple feedforward neural network.
In this article, we discuss several aspects of the source
separation problem. We give simple conditions on the network output
that, if satisfied, guarantee that source separation has been
obtained. Then we study adaptive approaches, in particular those
based on redundancy reduction and maximization of mutual
information. We show how the resulting updating rules are related
to the BCM theory of synaptic plasticity. Eventually we briefly
discuss extensions to the case of nonlinear mixtures. Throughout
this article, we take care to put into perspective our work with
other studies on source separation and redundancy reduction. In
particular we review algebraic solutions, pointing out their
simplicity but also their drawbacks.
(Copyright © The MIT Press)
back to the list without abstracts.
back to the list without abstracts.
Review paper on sparse coding in (auto)associative memories - in particular in Willshaw et al (1969) and Hopfield (1982) type models.
Related works:
"Associative memory: on the (puzzling) sparse coding limit",
J.-P. Nadal, Journal of Physics A: Mathematical and General, Vol. 24 (1991) pp. 1093-1101
(abstract and full paper available on IoP electronic journals web site).
"Information storage in sparsely-coded memory nets",
J.-P. Nadal and G. Toulouse, Network: Computation in Neural Systems, Vol. 1 (1990) pp. 61-74
abstract and full paper on the review web site. NB: initially published by IOP,
this journal has moved to Taylor & Francis.
back to the list of review articles and proceedings
We present a numerical study of a neural tree learning algorithm, the
trio-learning strategy. We study the behaviour of the algorithm as
a function of the size of the training set
(figure). The results show that a
limited number of examples can be used to estimate both the network performance
and the network complexity that would result from running the algorithm
on a large data set.
This work has been performed at Laboratoires d'Electronique Philips S.A.S. (LEP), Limeil-Brévannes, France.
back to the list without abstracts.
We consider a linear, one-layer feedforward neural network performing
a coding task. The goal of the network is to provide a
statistical neural representation that convey
as much information as possible on the input stimuli in noisy conditions.
We determine the family of synaptic couplings that maximizes
the mutual information between input and output distribution.
Optimization is performed under different constraints on the synaptic
efficacies. We analyze the dependence of the solutions on
input and output noises. This work goes beyond previous studies
of the same problem in that:
(i) we perform a detailed stability
analysis in order to find the global maxima of the mutual information;
(ii) we examine the properties of the optimal synaptic configurations
under different constraints;
(iii) we do not assume translational
invariance of the input data, as it is usually
done when input are assumed to be visual stimuli.
back to the list without abstracts.
Neural trees are constructive algorithms
which build decision trees whose nodes
are binary neurons. We propose a new learning scheme, "trio-learning", which
leads to a significant reduction in the tree complexity. Within the trio strategy, each node
of the tree is optimized by taking into account the knowledge
that it will be followed by two son nodes (figure). Moreover, trio-learning can be used to
build hybrid trees, with internal nodes and terminal nodes of different nature, for solving
any standard task (e.g. classification, regression, density estimation). Promising
results on a handwritten character classification are presented.
(Copyright © World Scientific Publishing Co.)
This work has been performed at Laboratoires d'Electronique Philips S.A.S. (LEP), Limeil-Brévannes, France.
back to the list without abstracts.
We investigate the consequences of maximizing information transfer
in a simple neural network (one input layer, one output layer),
focussing on the case of non linear transfer
functions. We assume that both receptive fields
(synaptic efficacies) and transfer functions can be
adapted to the environment.
The main result is that, for bounded and invertible transfer functions,
in the case of a vanishing additive output noise, and no
input noise, maximization of information (Linsker's infomax principle)
leads to a factorial code - hence to the same solution as
required by the redundancy reduction principle of Barlow, or,
in the signal processing language, to Independent Component Analysis (ICA).
We show also that this result is valid for linear,
more generally unbounded,
transfer functions, provided optimization is performed under an
additive constraint, that is which can be written as a
sum of terms, each one being specific to one output neuron.
Finally we study the effect of a non zero input noise. We find that,
at first order in the input noise, assumed to be small as compared
to the - small - output noise,
the above results are still valid, provided the output noise
is uncorrelated from one neuron to the other.
back to the list without abstracts.
We introduce an inferential approach to unsupervised learning which allows us to define an
optimal learning strategy. Applying these ideas to a simple,
previously studied model, we show that it is
impossible to detect structure in data until a critical number of examples
have been presented-an effect
which will be observed in all problems with certain underlying symmetries.
Thereafter, the advantage of
optimal learning over previously studied learning algorithms depends critically
upon the distribution of patterns; optimal learning may be exponentially faster.
Models with more subtle correlations are harder to
analyse, but in a simple limit of one such problem we calculate exactly the
efficacy of an algorithm similar to some used in practice, and compare it
to that of the optimal prescription.
(Copyright © Institute of Physics and IOP Publishing Limited)
back to the list without abstracts.
We study the ability of a simple neural network (a perceptron architecture,
no hidden units, binary outputs) to process information in the
context of an unsupervised learning task. The network is asked to
provide the best possible neural representation of a given input
distribution, according to some criterion taken from Information
Theory. We compare various optimization criteria that have been proposed :
maximum information transmission, minimum redundancy and closeness to
factorial code.
We show that for the perceptron one can compute
the maximal information that the code (the output neural representation)
can convey about the input. We show that one can use Statistical
Mechanics techniques, such as the replica techniques, to compute
the typical mutual information between input and output distributions.
More precisely, for a Gaussian input source with a given
correlation matrix, we compute
the typical mutual information when the couplings are chosen randomly. We
determine the correlations between the synaptic couplings
which maximize the gain of information. We analyse the results
in the case of a one dimensional receptive field.
back to the list without abstracts.
Reconsidering a recently introduced model of sequence-retrieving neural
network, we introduce appropriate analogues of the well-known
stabilities and show how these, together with two coupling parameters
$\lambda$ and $\vartheta$, entirely control the dynamics in the case of
strong dilution. The model is exactly solved and phase diagrams are
drawn for two different choices of the synaptic matrices; they reveal a
rich structure. We then briefly speculate as to the role of these
parameters within a more general framework.
(Copyright © Les Editions de Physique 1993)
back to the list without abstracts.
We exhibit a duality between two perceptrons that allows us to
compare the theoretical analysis of supervised and unsupervised
learning tasks - more exactly of parameter estimation
and encoding tasks. The first perceptron has one output and is asked
to learn a classification of p patterns. The second (dual)
perceptron has p outputs and is asked to transmit as much
information as possible on a distribution of inputs. We show in
particular that the maximum information that can be stored in the
couplings for the supervised learning task is equal to the maximum
information that can be transmitted by the dual perceptron.
(Copyright © The MIT Press)
back to the list without abstracts.
We demonstrate that formal neural networks techniques allow to build the simplest models compatible with a limited but systematic set of experimental data. The experimental system under study is the growth of mouse macrophage like cell lines under the combined influence of two ion channels, the growth factor receptor and adenylate cyclase. We conclude that 3 components out of 4 can be described by linear multithreshold automata. The remaining component behavior being non-monotonous necessitate the introduction of a fifth hidden variable, or of non-linear interactions.
back to the list without abstracts.
We study the information storage capacity of a simple perceptron in the error
regime. For random unbiased patterns the geometrical analysis gives a
logarithmic dependence of the information content in the asymptotic limit.
In
that regime the statistical physics approach, when used at the simplest level
of replica theory, does not give satisfactory results. However for
perceptrons with finite stability, the information content can be simply calculated
with statistical physics methods in a region above the critical storage
level, for biased as well as for unbiased patterns.
(Copyright © Institute of Physics and IOP Publishing Limited)
back to the list without abstracts.
Older journal articles: see here.